
I am a Ph.D. student at HKU supervised by Prof. Xihui Liu. Prior to that, I received my Bachelor’s degree from Renmin University of China, where I worked under the supervision of Prof. Jun He from Renmin University of China and Prof. Hongyan Liu from Tsinghua University. During my visit to HKUST, I was fortunate to be advised by Prof. Qifeng Chen, focusing on video generation. After that, I was an intern at MSRA, working with Dr. Junliang Guo and Tianyu He focusing on video generation and world simulator.
My research interests lie in building video world models. I am specifically interested in build interactive, real-time, and consistent video generation models that can serve as world simulators.
I am a highly self-motivated student with a deep passion for research and coding. I am eager to work on a series of influential projects to advance video generation as a foundation for world simulators.
You could find me through wuhaoyu556@connect.hku.hk.
🔥 News
- 2026.01.26: 🎉🎉 Geometry Forcing is accepted to ICLR26!
- 2025.09.22: 🎉🎉 Geometry Forcing is accepted to NeurIPS 2025 NextVid Workshop!
- 2025.07.11: 🎉🎉 We release Geometry Forcing!
- 2025.02.26: 🎉🎉 VideoDPO was accepted by CVPR2025!
- 2024.12.19: 🎉🎉 We make the VideoDPO paper and code public!
- 2024.11.01: 🎉🎉 We make the VideoTuna V0.1.0 public!
- 2023.07: 🎉🎉 Emotalk is accepted by ICCV23.
📝 Publications
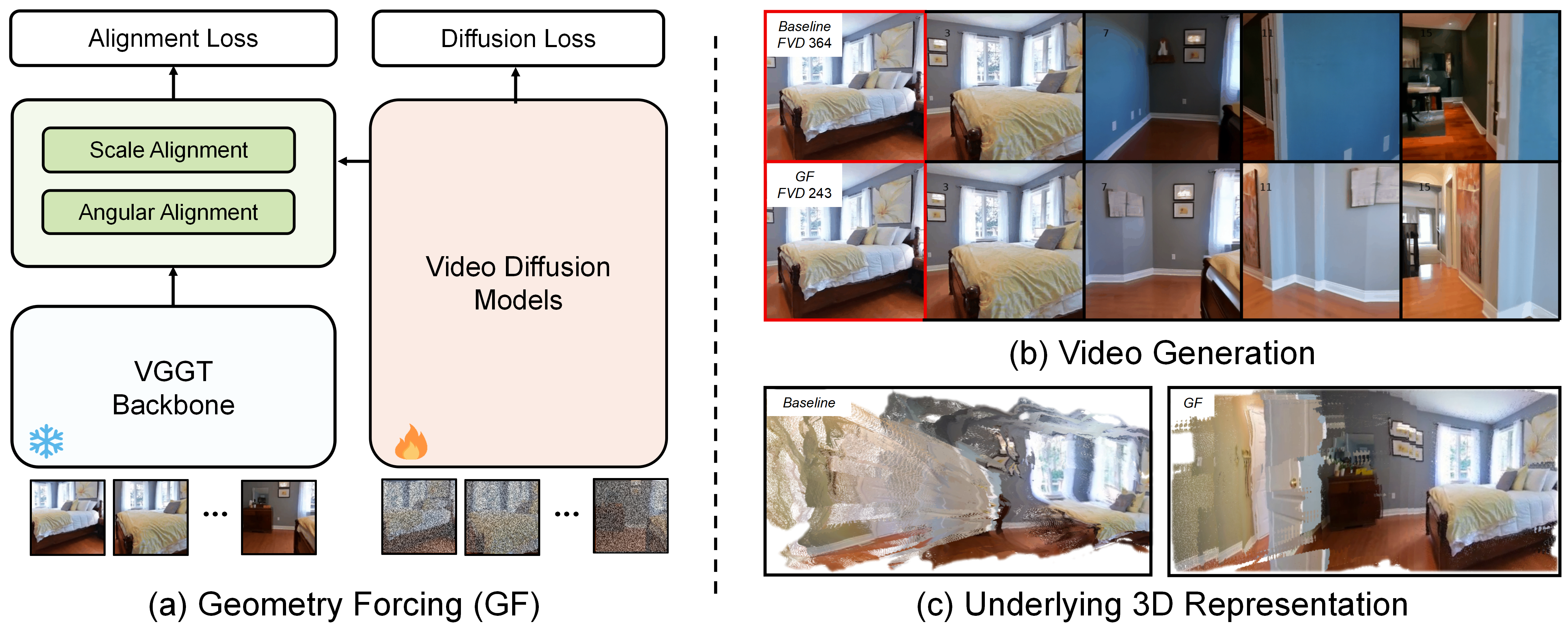
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Haoyu Wu*, Diankun Wu*, Tianyu He, Junliang Guo, Yang Ye, Yueqi Duan, Jiang Bian
- Geometry Forcing encourages video diffusion models to internalize latent 3D representations in order to bridge the gap between video diffusion models and the 3D nature of the real world.
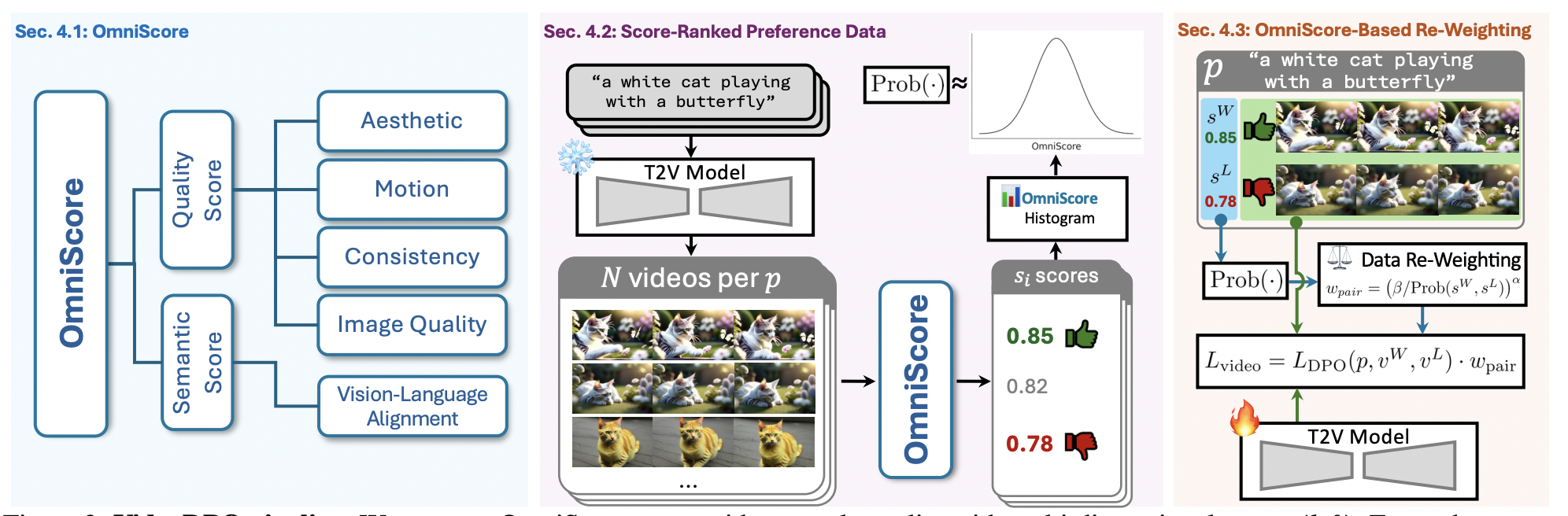
VideoDPO: Omni-Preference Alignment for Video Diffusion Generation
Runtao Liu*, Haoyu Wu*, Ziqiang Zheng, Chen Wei, Yingqing He, Renjie Pi, Qifeng Chen
- We propose a whole pipeline for DPO finetuning video diffusion models.
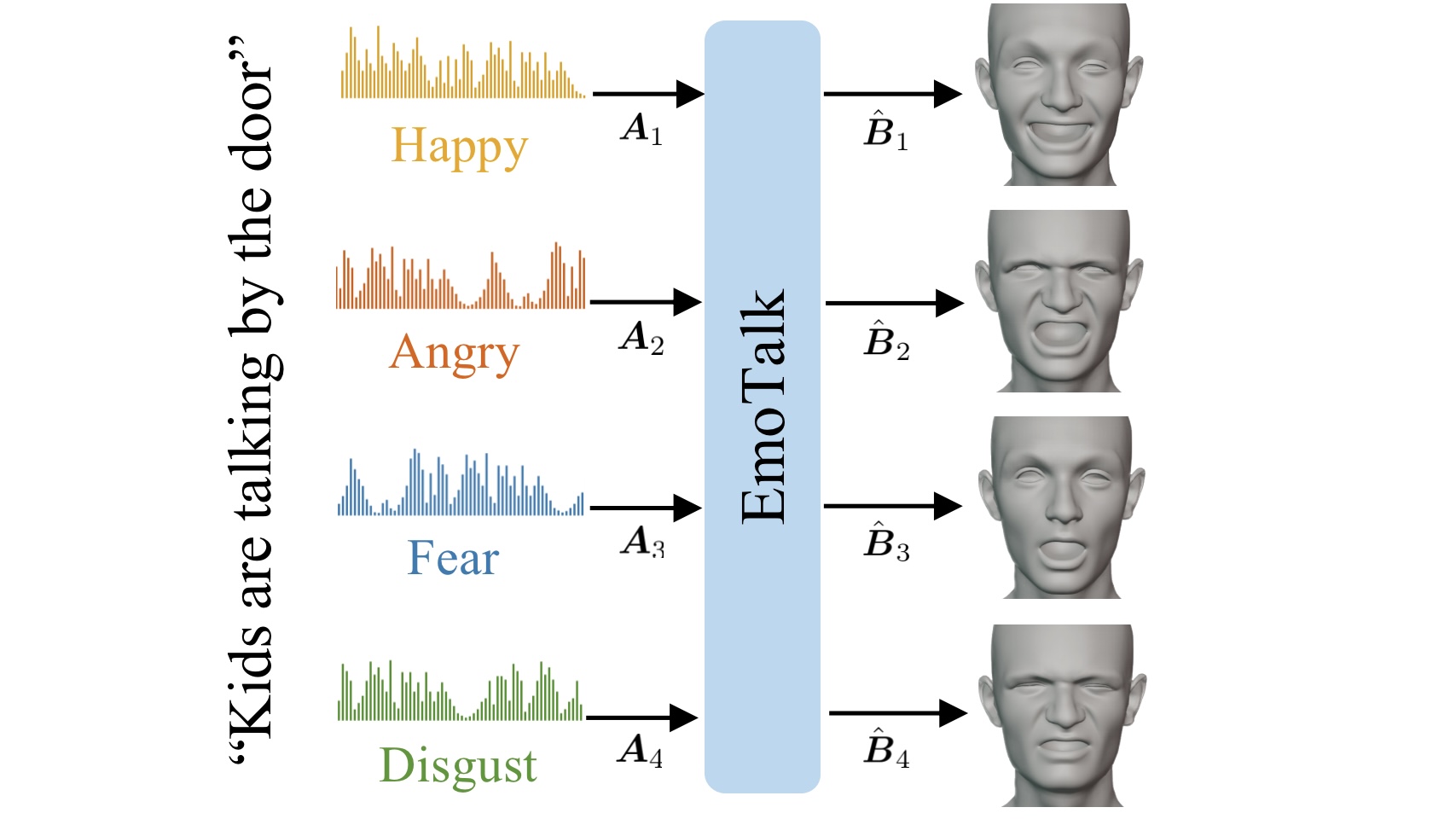
EmoTalk: Speech-Driven Emotional Disentanglement for 3D Face Animation
Ziqiao Peng, Haoyu Wu, Zhenbo Song, Hao Xu, Xiangyu Zhu, Hongyan Liu, Jun He, Zhaoxin Fan Project
- We propose an end-to-end neural network for speech-driven emotion-enhanced 3D facial animation.
- [preprint] VGG-Tex: A Vivid Geometry-Guided Facial Texture Estimation Model for High Fidelity Monocular 3D Face Reconstruction Haoyu Wu, Ziqiao Peng, Xukun Zhou, Yunfei Cheng, Jun He, Hongyan Liu, Zhaoxin Fan
📖 Educations
- 2021.09 - 2025.07, Undergraduate student at Renmin University of China, Beijing, China.
- 2024.07 - 2025.01, Visiting student supervised by Prof. Qifeng Chen at HKUST, Hong Kong, China.
💻 Internships
- 2024.11-2025.07, ML Group, Microsoft Research Asia
📕 Teaching Experiences
- 2024.09 - 2025.01, Teaching Assistant of Introduction to Computer System (I), Renmin University of China.
💬 Invited Talks
- 2023.01, “Introduction to Linux” of ”Missing Classes” series in RUC Computer Association
- 2023.08, AITIME Debate about 3D digital human development | [video]
🎖 Honors and Awards
- 2022.11 The Chinese Mathematical Competition,First Prize